Stop being woken up.Start sleeping through it.
LightsOut watches your infrastructure 24/7. When something fires, it does the first investigation so you never debug from scratch again.
You know this feeling.
Paged at 3am with zero context
SSH into 6 instances looking for clues
Copy-paste logs into ChatGPT, hoping
The fix was obvious — 40 minutes later
Every engineer has lived this. The fix exists. The problem is finding it at 3am, half-asleep, from scratch.
There's always
a friend online.
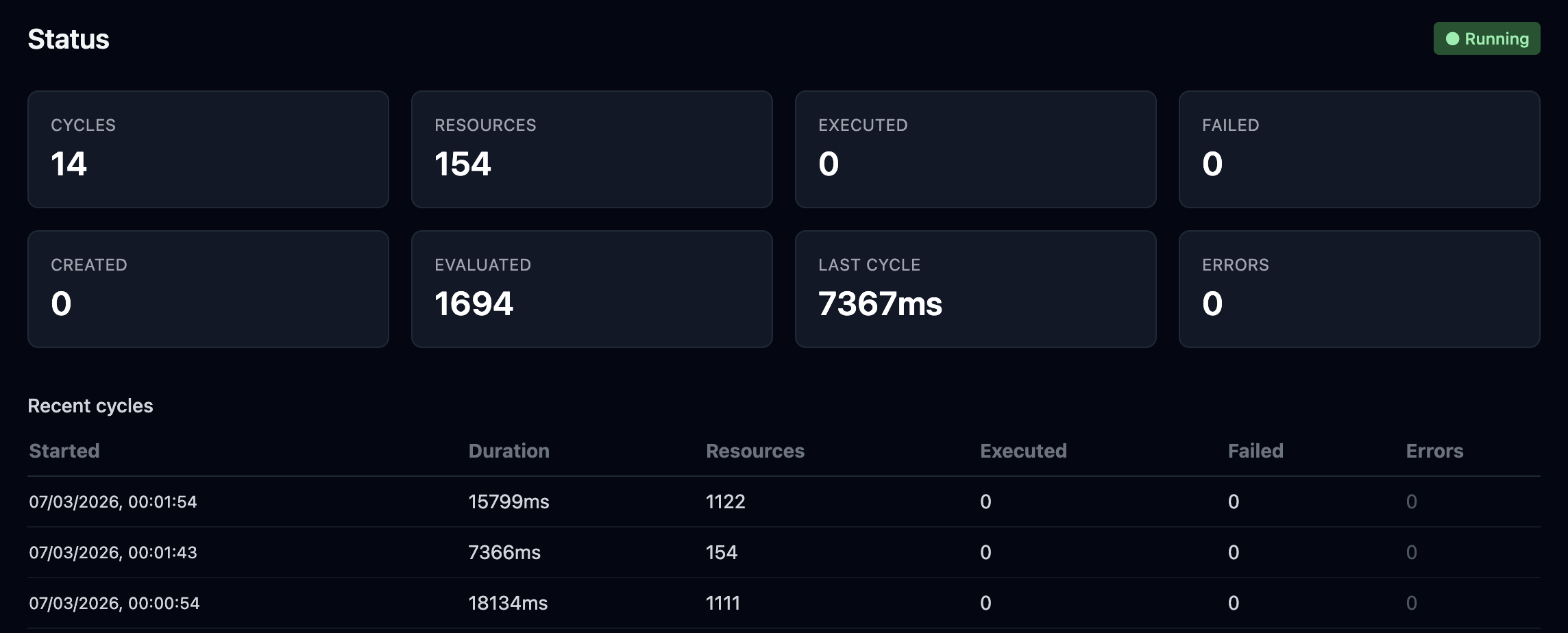
LightsOut never sleeps. Every 60 seconds, it checks every resource across every AWS region. The moment something looks wrong, it starts investigating — before you even know about it.
Never start a postmortem from scratch again.
How it works.
Deterministic. Auditable. Always transparent.
Collect
Polls all enabled AWS regions every 60 seconds
Evaluate
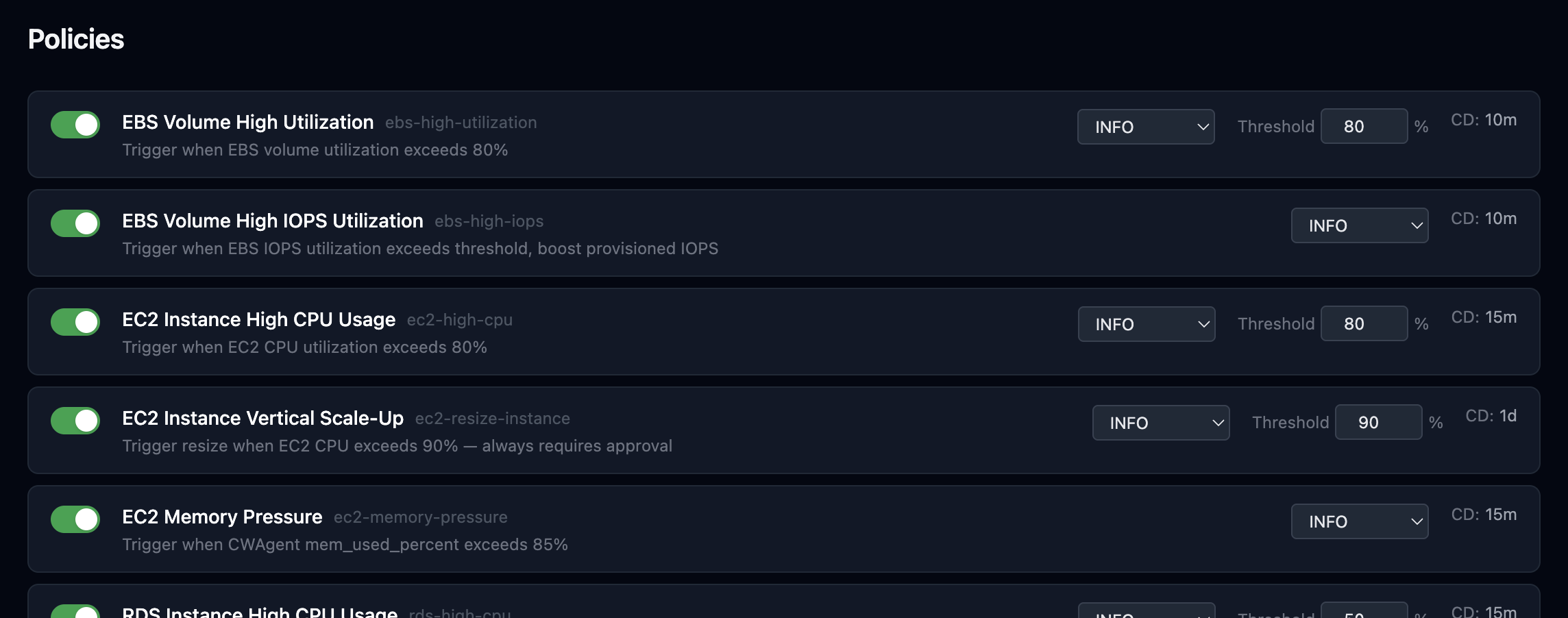
Policies check CPU, disk, IOPS, connections, health
Investigate
9 parallel root-cause checks run automatically
Notify
Slack alert with full context, approve with one click
Execute
Runs the fix. Notifies you of the result.
Powered by Claude AI — every decision explained in plain English.
9 checks run in parallel.
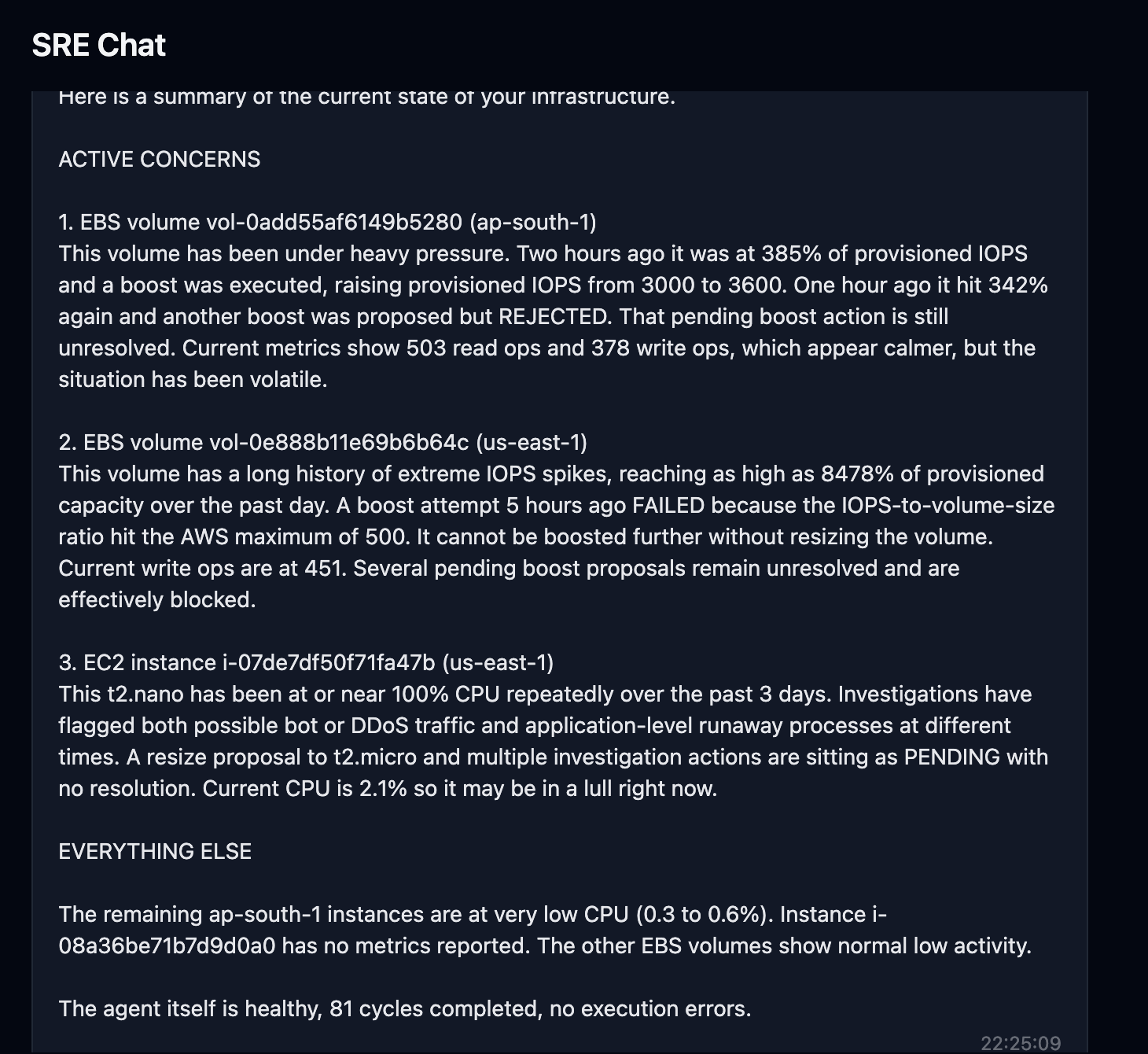
You get the answer, not the work.// AI summary
"High connection count correlates with deploy at 02:47. Performance Insights shows SELECT * queries on orders table consuming 78% of DB time. Recommend query optimization or read replica."
Watch it work.
Real investigation. Real execution. Your approval.
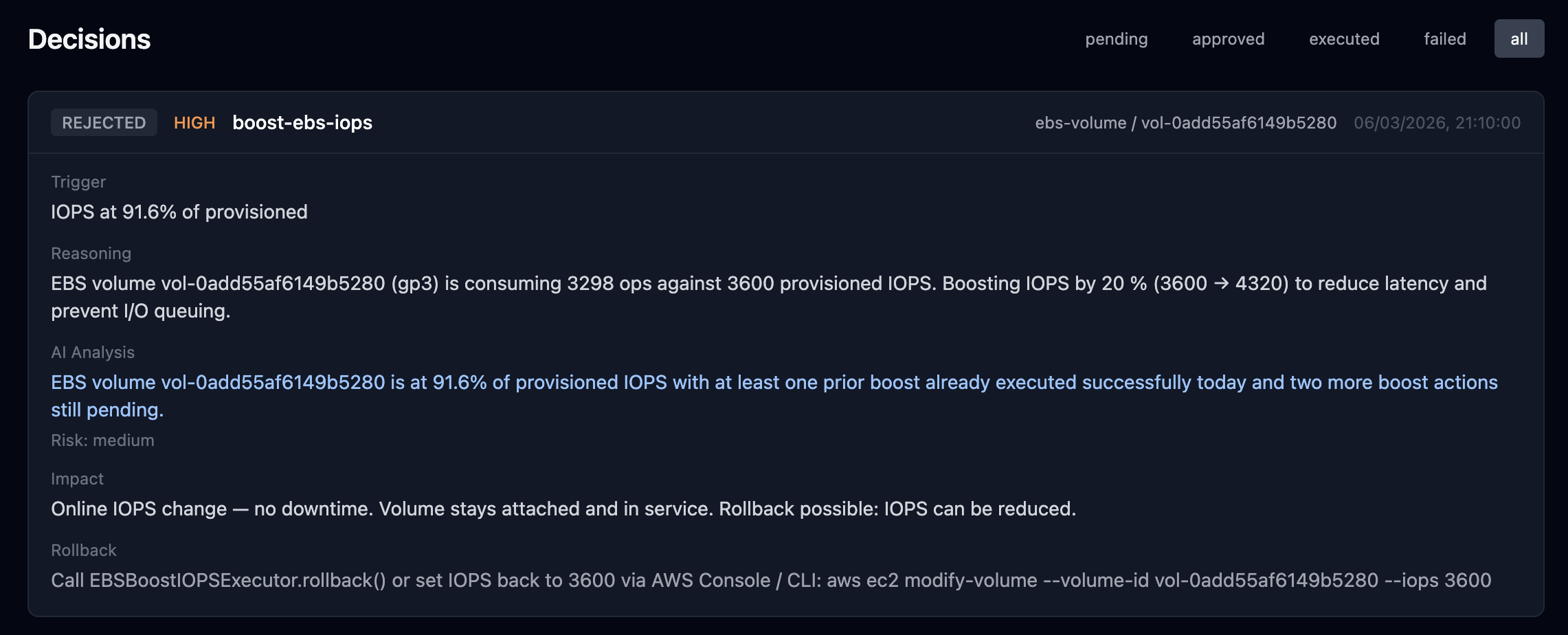
CPU climbs past threshold →
From first alert to executed fix — average time: 4m 12s
You decide
how much you trust it.Start cautious. Every policy can be in a different mode. Upgrade anytime.
Log everything, act on nothing.
Pure observability. Every decision is recorded, explained, and logged — without touching your infrastructure.
Read the analysis. Click to approve.
Get a Slack alert with full investigation context. You stay in control — one click to execute or reject. The sweet spot for most teams.
Execute immediately. No approval needed.
For teams that have built trust. Policies run and fix — you get notified after. One-click downgrade to APPROVAL anytime.
Always with
your approval.
Every decision includes what will happen, how to undo it, and why it was triggered. Destructive actions are hardcoded to APPROVAL mode. Always.
Never destructive
Terminate, delete, stop — these actions are hardcoded to APPROVAL mode. Always. No exceptions.
Full rollback plans
Every decision ships with a step-by-step undo procedure before any action is taken.
Dry-run mode
DRY_RUN=true runs the entire loop — collect, evaluate, investigate — without touching AWS.
Flap detection
Policy fires 3+ times in 60 minutes? Escalates to CRITICAL + APPROVAL automatically.
Runs inside your AWS account.
Your data never leaves.AWS
Full AWS SDK v3 · All regions
Slack
Socket Mode · No public URL
MongoDB
Optional · Graceful degradation
GCP
Coming SoonAzure
Coming SoonOracle
Coming SoonNo per-node agents. No public URLs. No new infrastructure. Socket Mode Slack — outbound WebSocket only.